
Cách crawl data từ website cho người mới
Vincent
13/07/2023
43
Cách crawl data là quy trình lấy các trường dữ liệu cần thiết từ website hoặc nguồn công khai, sau đó lưu thành bảng để phân tích. Người mới nên xác định dữ liệu cần lấy, kiểm tra API hoặc cấu trúc HTML, chọn công cụ phù hợp và tôn trọng điều khoản sử dụng, quyền riêng tư cùng giới hạn truy cập của nguồn.
Crawl data là gì?
Crawl data trong ngữ cảnh này là việc thu thập một tập dữ liệu cụ thể từ website để kiểm tra, phân tích hoặc tái sử dụng. Dữ liệu có thể là tiêu đề bài viết, URL, giá sản phẩm, danh mục, ngày đăng hoặc thông tin công khai khác. Mục tiêu là lấy đúng dữ liệu cần dùng theo một cấu trúc xác định.
Nhiều người dùng các cụm “crawl data”, “crawl web” và “web scraping” thay thế cho nhau. Tuy nhiên, các khái niệm này không hoàn toàn giống nhau. Việc hiểu đúng từ đầu giúp chọn công cụ phù hợp và tránh nhầm lẫn với kỹ thuật SEO.
|
Thuật ngữ |
Mục đích chính |
|
Crawl data |
Thu thập một tập dữ liệu cụ thể để sử dụng |
|
Web scraping |
Trích xuất nội dung hoặc trường dữ liệu từ trang web |
|
Web crawling |
Khám phá nhiều URL thông qua liên kết |
|
Google crawling |
Googlebot tìm, tải và xử lý nội dung để phục vụ quá trình lập chỉ mục |
Google crawling là hoạt động của công cụ tìm kiếm. Googlebot phát hiện URL, tải trang và xử lý nội dung trước khi hệ thống có thể cân nhắc lập chỉ mục. Trong khi đó, crawl data phục vụ nhu cầu của người dùng hoặc doanh nghiệp, chẳng hạn tổng hợp danh sách bài viết để audit content hoặc xuất danh mục sản phẩm công khai thành bảng dữ liệu.
Vì vậy, nếu mục tiêu là giúp Google tìm và index website tốt hơn, cần xem các vấn đề như sitemap, robots.txt, internal link và canonical. Nhưng nếu mục tiêu của bạn là lấy dữ liệu từ một nguồn web để nghiên cứu hoặc quản lý, đây mới là bài toán crawl data. Có thể đọc thêm về crawl là gì để phân biệt rõ hơn hai hướng này.
Khi nào nên crawl data và khi nào không nên?
Crawl data phù hợp khi bạn biết rõ dữ liệu cần lấy, nguồn dữ liệu hợp lệ và mục đích sử dụng sau đó. Ngược lại, không nên tự động thu thập dữ liệu chứa thông tin cá nhân hoặc bị giới hạn quyền truy cập. Một quy trình tốt luôn bắt đầu từ quyền sử dụng dữ liệu, không phải từ công cụ.
Ví dụ, team marketing có thể cần tổng hợp title, URL và ngày đăng của các bài viết trên website để rà soát content. Một doanh nghiệp bán hàng cũng có thể cần xuất danh sách sản phẩm công khai để kiểm tra thuộc tính, danh mục hoặc URL. Đây là các use case rõ ràng vì dữ liệu có mục đích cụ thể.
Tuy nhiên, việc crawl dữ liệu không nên được xem là cách lấy mọi thông tin có thể nhìn thấy trên internet. Một trang công khai vẫn có thể có điều khoản sử dụng riêng, giới hạn kỹ thuật hoặc dữ liệu không nên thu thập hàng loạt.
|
Tình huống |
Có nên crawl? |
Hướng xử lý phù hợp |
|
Website của chính doanh nghiệp |
Nên |
Dùng export, API hoặc Python |
|
Nguồn có API chính thức |
Nên ưu tiên |
Đọc tài liệu API và dùng đúng quota |
|
Danh sách công khai, ít trang |
Có thể |
Dùng công cụ no-code hoặc script đơn giản |
|
Dữ liệu nằm sau đăng nhập |
Không tự ý |
Xin quyền hoặc dùng kênh chính thức |
|
Dữ liệu cá nhân |
Cần xem xét kỹ |
Kiểm tra quyền, mục đích và cách lưu trữ |
|
CAPTCHA, paywall hoặc cơ chế bảo vệ |
Không cố vượt |
Tìm API, dữ liệu export hoặc liên hệ nguồn |
Một nguyên tắc thực tế là: nếu không thể giải thích rõ dữ liệu này sẽ được dùng để làm gì, thì chưa nên bắt đầu crawl. Dữ liệu càng nhiều càng không đồng nghĩa với phân tích tốt hơn. Dữ liệu đúng, có cấu trúc và phù hợp mục tiêu mới giúp ích cho công việc.
Trước khi crawl data, cần xác định những gì?
Trước khi chọn Python, extension hay nền tảng no-code, cần xác định bốn yếu tố:
- trường dữ liệu
- nguồn dữ liệu
- quy mô
- định dạng đầu ra
Bước chuẩn bị này giúp tránh tình trạng lấy được hàng nghìn dòng dữ liệu nhưng không thể sử dụng vì thiếu cột, sai định dạng hoặc lẫn quá nhiều thông tin không liên quan.
Ghi rõ các trường cần lấy
Chẳng hạn, một content audit cơ bản có thể chỉ cần URL, tiêu đề, meta description, ngày cập nhật và trạng thái HTTP. Nếu mục tiêu là kiểm tra danh mục sản phẩm, dữ liệu có thể gồm tên sản phẩm, URL, giá niêm yết và tình trạng hiển thị.
Xác định nguồn dữ liệu
Có nguồn cung cấp API, có nguồn cho phép export CSV hoặc Excel, trong khi một số nguồn chỉ hiển thị dữ liệu trên giao diện. API hoặc file export thường là lựa chọn ổn định hơn vì dữ liệu đã có cấu trúc sẵn.
Ước tính quy mô
Một danh sách 30 bài viết có thể xử lý thủ công hoặc bằng công cụ no-code. Tuy nhiên, một website có vài nghìn URL sẽ cần quy trình tự động hóa, làm sạch dữ liệu và kiểm tra lỗi kỹ hơn.
Xác định đầu ra cần dùng
CSV phù hợp khi cần mở bằng Excel hoặc Google Sheets. JSON phù hợp khi dữ liệu cần đưa tiếp vào hệ thống. Nếu dữ liệu chỉ phục vụ kiểm tra nhanh, một bảng Google Sheets có thể đã đủ.
Có 3 cách crawl data phổ biến
Ba hướng phổ biến nhất là dùng API, dùng công cụ no-code và dùng Python.
- API thường là lựa chọn ưu tiên nếu nguồn dữ liệu cung cấp chính thức
- Công cụ no-code phù hợp với tác vụ đơn giản
- Python hữu ích hơn khi cần xử lý nhiều trang hoặc làm sạch dữ liệu theo quy tắc riêng
|
Phương pháp |
Phù hợp với ai |
Điểm mạnh |
Điểm cần lưu ý |
|
API chính thức |
Team kỹ thuật hoặc dữ liệu có cấu trúc |
Ổn định, rõ trường dữ liệu |
Có thể cần API key hoặc quota |
|
Công cụ no-code |
Người mới, dữ liệu đơn giản |
Dễ thử nghiệm, ít cần code |
Khó duy trì khi website thay đổi |
|
Python |
Người cần tự động hóa |
Linh hoạt, dễ mở rộng workflow |
Cần hiểu HTML, request và xử lý lỗi |
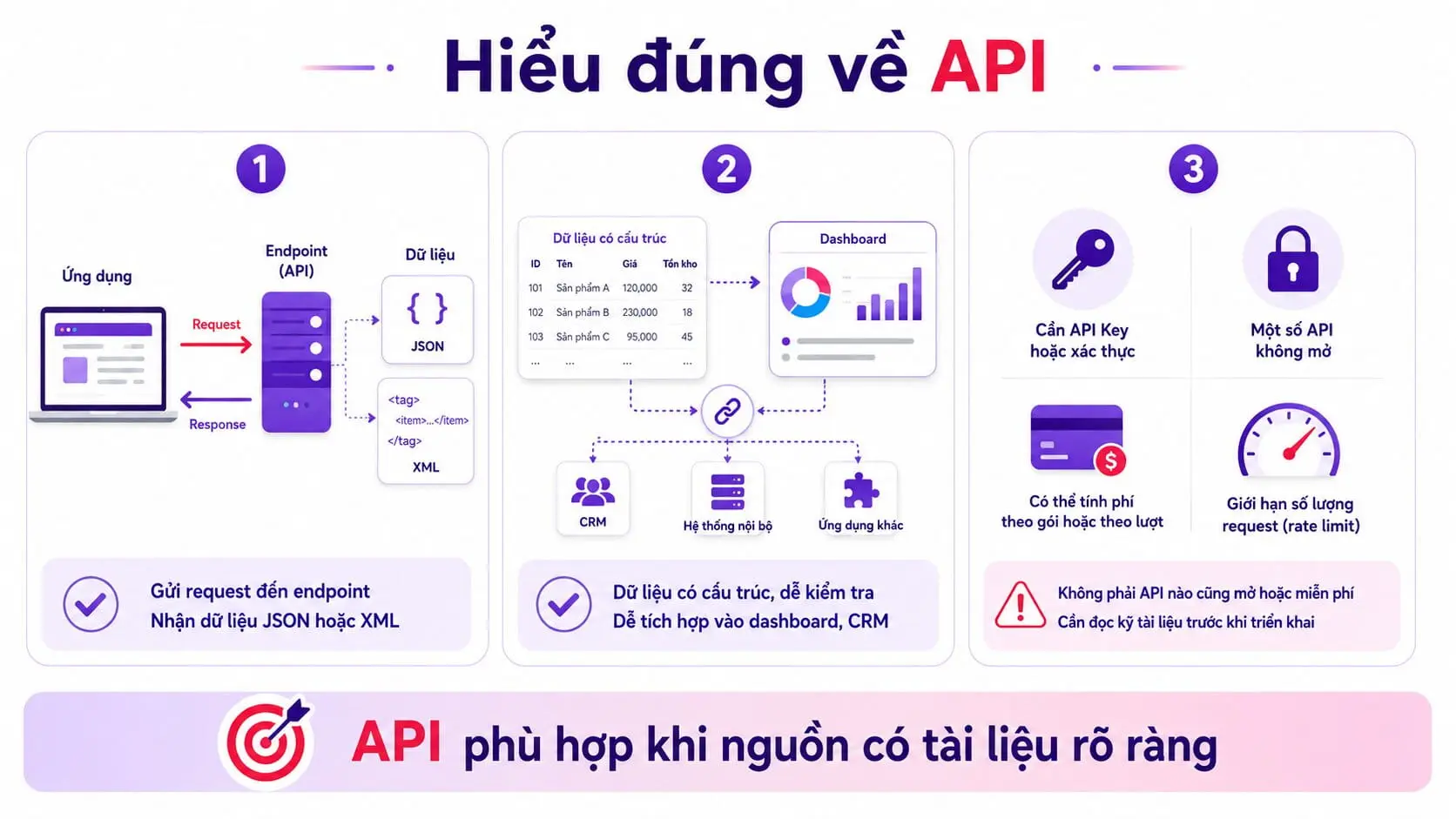
Dùng API khi nguồn có dữ liệu chính thức
API là giao diện cho phép hệ thống trao đổi dữ liệu theo cấu trúc được xác định. Thay vì đọc giao diện web rồi tìm từng phần tử HTML, bạn gửi request đến endpoint và nhận về dữ liệu dạng JSON hoặc XML.
Đây thường là lựa chọn tốt hơn khi nguồn có tài liệu API rõ ràng. Dữ liệu dễ kiểm tra hơn, ít phụ thuộc vào giao diện và có thể tích hợp trực tiếp vào dashboard, CRM hoặc hệ thống nội bộ.
Tuy nhiên, API không phải lúc nào cũng miễn phí hoặc mở cho mọi người dùng. Một số API yêu cầu đăng ký ứng dụng, xác thực bằng key, giới hạn số request hoặc chỉ cho truy cập một phần dữ liệu. Vì vậy, cần đọc kỹ tài liệu của từng nguồn trước khi triển khai.
Dùng công cụ no-code khi dữ liệu đơn giản
Công cụ no-code phù hợp khi cần lấy dữ liệu từ một vài trang có cấu trúc lặp lại. Ví dụ, bạn muốn trích xuất tiêu đề, đường dẫn và ngày đăng từ danh sách bài viết công khai. Các công cụ dạng chọn phần tử trên màn hình có thể giúp hoàn thành việc này mà không cần viết code.
Điểm mạnh của cách làm này là nhanh và dễ thử. Người làm marketing hoặc content có thể xem trước kết quả, loại bỏ cột không cần thiết rồi xuất file CSV. Đây là lựa chọn phù hợp cho tác vụ một lần hoặc quy mô nhỏ.
Dù vậy, công cụ no-code thường phụ thuộc vào giao diện. Khi website đổi bố cục, selector có thể không còn hoạt động. Vì vậy, nếu cần chạy lại theo lịch hoặc xử lý hàng nghìn trang, Python hoặc API thường đáng cân nhắc hơn.
Dùng Python khi cần lặp lại và tùy chỉnh
Python phù hợp khi bạn cần thu thập dữ liệu theo quy trình lặp lại. Chẳng hạn, team SEO muốn mỗi tháng xuất danh sách URL, title, heading và meta description để so sánh thay đổi. Một script Python có thể giúp giảm thao tác thủ công và chuẩn hóa định dạng đầu ra.
Với Python, workflow cơ bản thường gồm ba phần. Đầu tiên, gửi request đến trang hoặc API. Sau đó, đọc HTML hoặc JSON để lấy các trường cần thiết. Cuối cùng, làm sạch dữ liệu và xuất thành CSV.
Thư viện requests thường được dùng để gửi HTTP request. Beautiful Soup giúp phân tích HTML và chọn các phần tử bằng selector. Python cũng có sẵn module csv để ghi dữ liệu dạng bảng ra file.
Cách crawl data bằng Python qua một ví dụ cơ bản
Với một trang có dữ liệu công khai và cấu trúc ổn định, cách crawl data bằng Python thường gồm sáu bước: xác định trường dữ liệu, kiểm tra nguồn, gửi request, chọn phần tử HTML, làm sạch kết quả và xuất CSV. Ví dụ dưới đây minh họa cách lấy tiêu đề, URL và ngày đăng từ một trang danh sách bài viết.
Bước 1: Xác định dữ liệu cần lấy
Một lỗi phổ biến là mở website rồi cố lấy mọi thứ có thể nhìn thấy. Cách này khiến file đầu ra lộn xộn và khó kiểm tra.
Ví dụ này chỉ lấy ba trường:
- Tiêu đề bài viết.
- URL bài viết.
- Ngày đăng hoặc ngày cập nhật.
Ba trường này đủ để tạo một danh sách nội dung cơ bản. Sau đó, bạn có thể thêm các cột khác như category, tác giả hoặc mô tả ngắn khi thực sự cần.
Bước 2: Kiểm tra dữ liệu nằm ở đâu
Mở trang cần kiểm tra trong trình duyệt. Sau đó, nhấp chuột phải vào tiêu đề bài viết và chọn Inspect hoặc Kiểm tra. Mục tiêu là xem phần tử HTML chứa dữ liệu có class, thẻ hoặc cấu trúc lặp lại nào.
Ví dụ, mỗi bài có thể nằm trong một thẻ như:
<article class=”article-card”>
<h2><a href=”/bai-viet-a/”>Tiêu đề bài viết</a></h2>
<time datetime=”2026-07-01″>01/07/2026</time>
</article>
Trong trường hợp này, .article-card là selector cho từng bài. h2 a là vị trí lấy tiêu đề và URL. Còn time là vị trí lấy ngày đăng.
Nếu bạn không thấy dữ liệu trong HTML ban đầu, hãy mở Developer Tools, vào tab Network rồi lọc Fetch/XHR. Tải lại trang và kiểm tra xem website có nhận dữ liệu dạng JSON từ một request riêng hay không. Nếu có API công khai hoặc endpoint được phép dùng, đây thường là nguồn dữ liệu phù hợp hơn HTML giao diện.
Bước 3: Cài thư viện cần thiết
Mở Terminal hoặc Command Prompt, sau đó cài hai thư viện:
python -m pip install requests beautifulsoup4
requests giúp gửi request để nhận nội dung trang. Beautiful Soup giúp đọc HTML thành cấu trúc có thể tìm kiếm. Python dùng module csv có sẵn để ghi dữ liệu ra file bảng.
Bước 4: Gửi request và đọc HTML
Đoạn code dưới đây dùng một URL minh họa. Bạn cần thay URL và selector theo cấu trúc thật của nguồn dữ liệu được phép sử dụng.
import csv
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
url = “https://website-cua-ban.example/danh-sach-bai-viet”
response = requests.get(url, timeout=20)
response.raise_for_status()
soup = BeautifulSoup(response.text, “html.parser”)
timeout=20 giúp script không chờ vô hạn nếu máy chủ phản hồi chậm. Còn raise_for_status() giúp báo lỗi khi request nhận phản hồi lỗi như 404 hoặc 500, thay vì tiếp tục xử lý một trang không hợp lệ.
Bước 5: Trích xuất và làm sạch dữ liệu
Sau khi có HTML, script cần lặp qua từng card bài viết. Trong ví dụ này, mỗi bài nằm trong .article-card.
rows = []
for card in soup.select(“.article-card”):
title_link = card.select_one(“h2 a”)
date_tag = card.select_one(“time”)
if not title_link:
continue
title = title_link.get_text(strip=True)
article_url = urljoin(url, title_link.get(“href”, “”))
published_date = date_tag.get_text(strip=True) if date_tag else “”
if not title or not article_url:
continue
rows.append({
“title”: title,
“url”: article_url,
“published_date”: published_date
})
Phần if not title_link giúp bỏ qua những phần tử không có tiêu đề hợp lệ. Điều này hữu ích vì nhiều trang có thể chứa card quảng cáo, block giới thiệu hoặc bài nổi bật với cấu trúc khác.
urljoin() giúp chuyển URL tương đối thành URL đầy đủ. Ví dụ, /bai-viet-a/ sẽ trở thành địa chỉ hoàn chỉnh dựa trên domain của trang đang crawl.
Bước 6: Xuất dữ liệu thành CSV
Khi đã có danh sách dữ liệu, bạn có thể ghi ra CSV như sau:
with open(“danh-sach-bai-viet.csv”, “w”, newline=””, encoding=”utf-8-sig”) as file:
writer = csv.DictWriter(
file,
fieldnames=[“title”, “url”, “published_date”]
)
writer.writeheader()
writer.writerows(rows)
print(f”Đã lưu {len(rows)} dòng dữ liệu.”)
Sau khi chạy script, hãy mở file CSV và kiểm tra ngẫu nhiên vài dòng đầu. Cần xem tiêu đề có bị thiếu không, URL có đúng domain không và ngày đăng có bị lẫn với nội dung khác không.
Đừng chạy script trên hàng nghìn URL ngay từ lần đầu. Hãy thử với một trang danh sách trước. Khi kết quả đúng, mới mở rộng sang phân trang hoặc nhiều category.
Vì sao code crawl data không lấy được dữ liệu?
Khi script chạy nhưng kết quả trống, nguyên nhân thường không nằm ở Python. Vấn đề phổ biến hơn là dữ liệu tải bằng JavaScript, selector không còn đúng hoặc nguồn yêu cầu quyền truy cập. Cần kiểm tra nguồn dữ liệu trước khi thay đổi code liên tục.
|
Tình huống |
Nguyên nhân thường gặp |
Hướng xử lý phù hợp |
|
HTML không có dữ liệu nhìn thấy trên web |
Nội dung tải bằng JavaScript |
Kiểm tra Fetch/XHR hoặc API công khai |
|
Request trả về lỗi |
URL sai, server lỗi hoặc cần xác thực |
Kiểm tra status code và quyền truy cập |
|
Dữ liệu thiếu khi sang trang sau |
Website có pagination hoặc lazy load |
Xác định quy tắc phân trang trước |
|
Nhiều dòng bị trùng |
Card lặp, URL lặp hoặc block quảng cáo |
Loại trùng theo URL hoặc mã định danh |
|
Script từng chạy được nhưng nay lỗi |
Website đổi giao diện |
Kiểm tra lại HTML và cập nhật selector |
|
Dữ liệu hiển thị sau đăng nhập |
Nguồn cần quyền sử dụng |
Dùng API hoặc kênh được cấp phép |
Một website hiện đại có thể hiển thị nội dung sau khi trình duyệt chạy JavaScript. Khi dùng requests, bạn chỉ nhận HTML mà server trả về ban đầu. Nếu dữ liệu được tải sau đó qua API, HTML có thể gần như trống dù người dùng vẫn nhìn thấy nội dung trên trình duyệt.
Trong trường hợp này, không nên cố mô phỏng đăng nhập, vượt CAPTCHA hoặc tìm cách né cơ chế bảo vệ. Cách phù hợp hơn là kiểm tra xem nguồn có API, file export hoặc quy trình cấp quyền chính thức hay không.
Những nguyên tắc cần biết trước khi crawl data
Crawl data nên được thực hiện với nguồn hợp lệ, mục tiêu rõ ràng và tần suất hợp lý. Robots.txt có thể cho crawler biết phần nào chủ website muốn bot truy cập, nhưng đây không phải giấy phép sử dụng dữ liệu hay cơ chế cấp quyền truy cập.
Trước khi chạy crawl ở quy mô lớn, nên kiểm tra các điểm sau:
- Ưu tiên API chính thức hoặc dữ liệu được phép export.
- Chỉ lấy dữ liệu thực sự cần cho mục tiêu phân tích.
- Không tự ý thu thập dữ liệu cá nhân hoặc dữ liệu sau đăng nhập.
- Không cố vượt CAPTCHA, paywall hoặc cơ chế bảo vệ của website.
- Không gửi request dồn dập gây tải không cần thiết cho máy chủ.
- Lưu lại nguồn, thời điểm lấy dữ liệu và mục đích sử dụng.
Các nguyên tắc này không chỉ giúp hạn chế rủi ro. Chúng còn giúp luồng làm việc dễ kiểm soát hơn. Khi nguồn dữ liệu thay đổi hoặc có câu hỏi về độ chính xác, team có thể truy lại dữ liệu đến từ đâu và được lấy vào thời điểm nào.
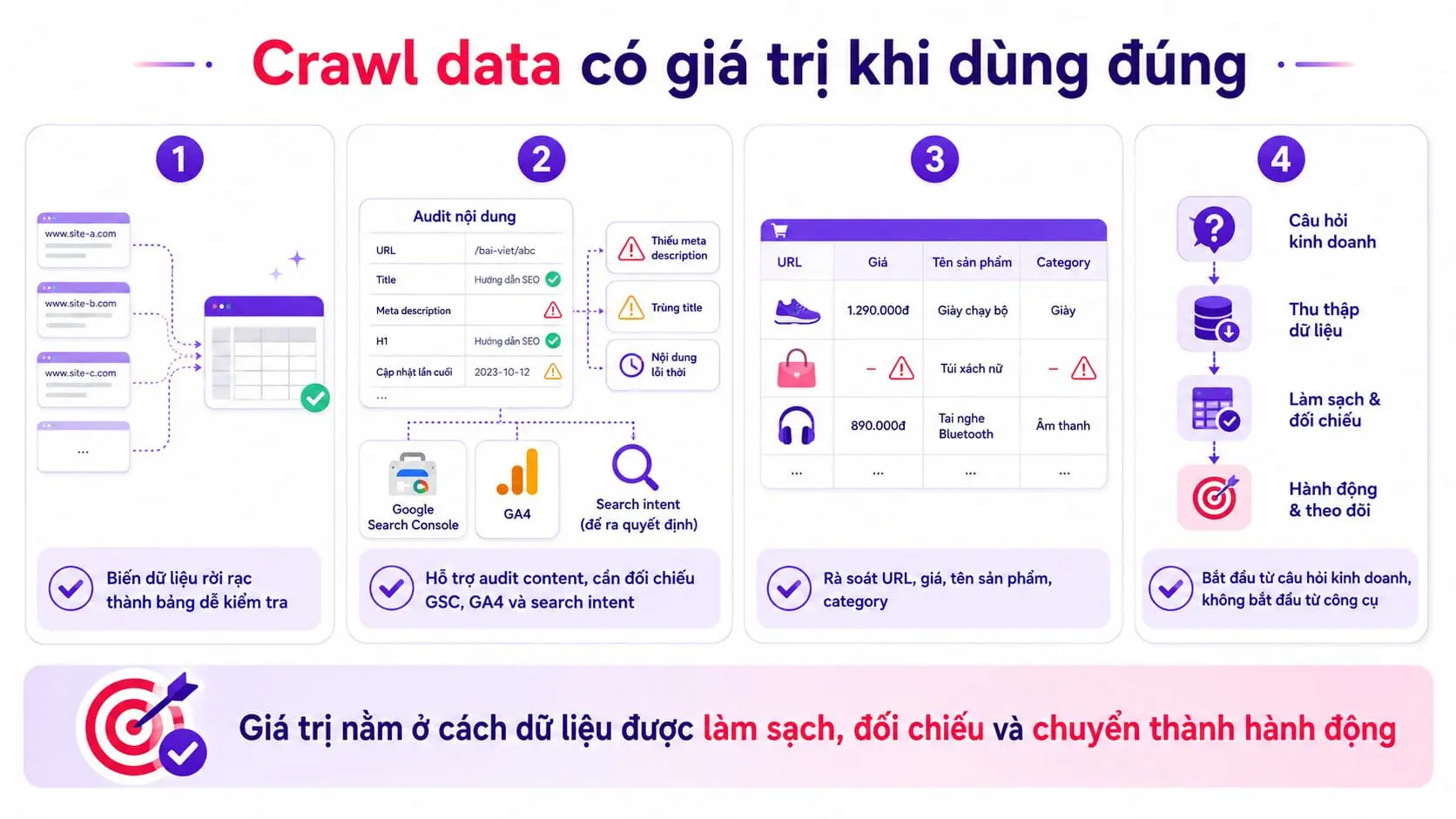
Crawl data có thể hỗ trợ marketing và SEO như thế nào?
Crawl data có giá trị khi biến dữ liệu rời rạc thành bảng có thể kiểm tra và ra quyết định. Với đội ngũ marketing hoặc SEO, dữ liệu thường dùng không phải thông tin cá nhân của người dùng mà là dữ liệu công khai từ chính website hoặc nguồn được phép sử dụng.
Một ví dụ phổ biến là crawl danh sách URL, title, meta description và heading từ website để tìm trang thiếu metadata, title trùng hoặc nội dung chưa được cập nhật. Dữ liệu này có thể hỗ trợ audit content, nhưng vẫn cần kết hợp với Google Search Console, Google Analytics 4 và đánh giá search intent trước khi đưa ra quyết định.
Crawl data cũng hữu ích khi kiểm tra cấu trúc danh mục. Ví dụ, website thương mại điện tử có thể xuất danh sách sản phẩm công khai để rà soát URL, giá hiển thị, tên sản phẩm hoặc category. Mục tiêu là phát hiện dữ liệu thiếu và lỗi vận hành, không phải tự động sao chép nội dung của website khác.
Một workflow tốt luôn bắt đầu từ câu hỏi kinh doanh. Bạn cần dữ liệu để kiểm tra điều gì? Sau đó mới chọn cách lấy dữ liệu phù hợp. Công cụ chỉ là phương tiện. Giá trị nằm ở cách dữ liệu được làm sạch, đối chiếu và chuyển thành hành động.
Câu hỏi thường gặp về cách crawl data
Crawl data và web scraping có giống nhau không?
Crawl data thường được dùng để chỉ hoạt động thu thập dữ liệu từ website. Web scraping cụ thể hơn, tức là trích xuất các trường như tiêu đề, giá, URL hoặc ngày đăng từ giao diện web hay HTML. Trong thực tế, hai thuật ngữ có thể chồng lấp, nhưng mục tiêu cần rõ: lấy dữ liệu cụ thể hay khám phá nhiều URL.
Người không biết code có crawl data được không?
Có. Người không biết code có thể bắt đầu bằng file export, API có giao diện sẵn hoặc công cụ no-code dạng chọn phần tử trên trang. Tuy nhiên, cách này phù hợp hơn với dữ liệu đơn giản và quy mô nhỏ. Khi cần chạy lặp lại hoặc xử lý nhiều trường dữ liệu, Python thường giúp workflow ổn định hơn.
Khi nào nên dùng API thay vì crawl website?
Nên ưu tiên API khi nguồn cung cấp dữ liệu chính thức, có tài liệu rõ ràng và cho phép truy cập theo mục đích của bạn. API thường trả dữ liệu có cấu trúc, ít phụ thuộc vào giao diện và dễ tích hợp hơn. Crawl HTML phù hợp hơn khi không có API nhưng dữ liệu công khai, cần lấy ít trường và cấu trúc trang ổn định.
Robots.txt có đồng nghĩa với được phép crawl không?
Không. Robots.txt chủ yếu đưa ra chỉ dẫn cho crawler về phần website mà chủ sở hữu muốn bot truy cập hoặc tránh truy cập. Tệp này không thay thế điều khoản sử dụng, quyền truy cập, cơ chế đăng nhập hoặc yêu cầu liên quan đến dữ liệu cá nhân. Vì vậy, vẫn cần kiểm tra bối cảnh và quyền sử dụng dữ liệu.
Vì sao request trả về HTML nhưng không có dữ liệu cần lấy?
Nguyên nhân thường là dữ liệu được tải bằng JavaScript sau khi trang mở. requests chỉ nhận HTML ban đầu từ server, nên có thể không chứa các card sản phẩm hoặc bài viết mà bạn nhìn thấy trên trình duyệt. Khi đó, cần kiểm tra Network, Fetch/XHR hoặc API công khai thay vì tiếp tục đổi selector trong HTML.
Crawl data có giúp Google index website nhanh hơn không?
Không. Crawl data là hoạt động người dùng hoặc hệ thống lấy dữ liệu từ một nguồn web để phân tích. Google index là quá trình Googlebot phát hiện URL, tải nội dung và xử lý thông tin cho hệ thống tìm kiếm. Hai hoạt động này khác mục tiêu, công cụ và cách triển khai.
Kết luận
Cách crawl data hiệu quả không bắt đầu từ việc chọn một công cụ thật phức tạp. Nó bắt đầu từ việc xác định dữ liệu cần lấy, kiểm tra nguồn phù hợp và chọn phương pháp tạo ra kết quả ổn định nhất.
API nên là lựa chọn đầu tiên khi nguồn có hỗ trợ chính thức, công cụ no-code phù hợp để thử nhanh với dữ liệu đơn giản, trong khi Python hữu ích khi cần tự động hóa và kiểm soát quy trình. Dù chọn hướng nào, dữ liệu chỉ thực sự có giá trị khi được lấy có trách nhiệm, làm sạch đúng cách và dùng cho một quyết định cụ thể.

BÀI VIẾT MỚI NHẤT
- Spam mail là gì? Tìm hiểu nguyên nhân và phòng tránh spam mail
- Tìm hiểu cấu trúc 4ps trong content writing? Bí quyết giúp content thu hút
- Hướng dẫn kiếm tiền từ Facebook Ad Breaks hiệu quả
- Kế hoạch Facebook marketing: Vai trò quan trọng và cách triển khai phù hợp
- Bật Mí Cách Chạy Quảng Cáo Instagram Hiệu Quả Nhất
Đọc thêm