
Robots.txt là gì và khi nào website cần dùng file này?
Vincent
10/06/2023
30
Robots.txt là tệp văn bản đặt ở thư mục gốc website để hướng dẫn crawler như Googlebot được phép hoặc không được phép truy cập một số đường dẫn. File này hỗ trợ kiểm soát crawl, khai báo sitemap và giảm request không cần thiết, nhưng không phải công cụ bảo mật hay lệnh chặn index tuyệt đối.
Robots.txt là gì?
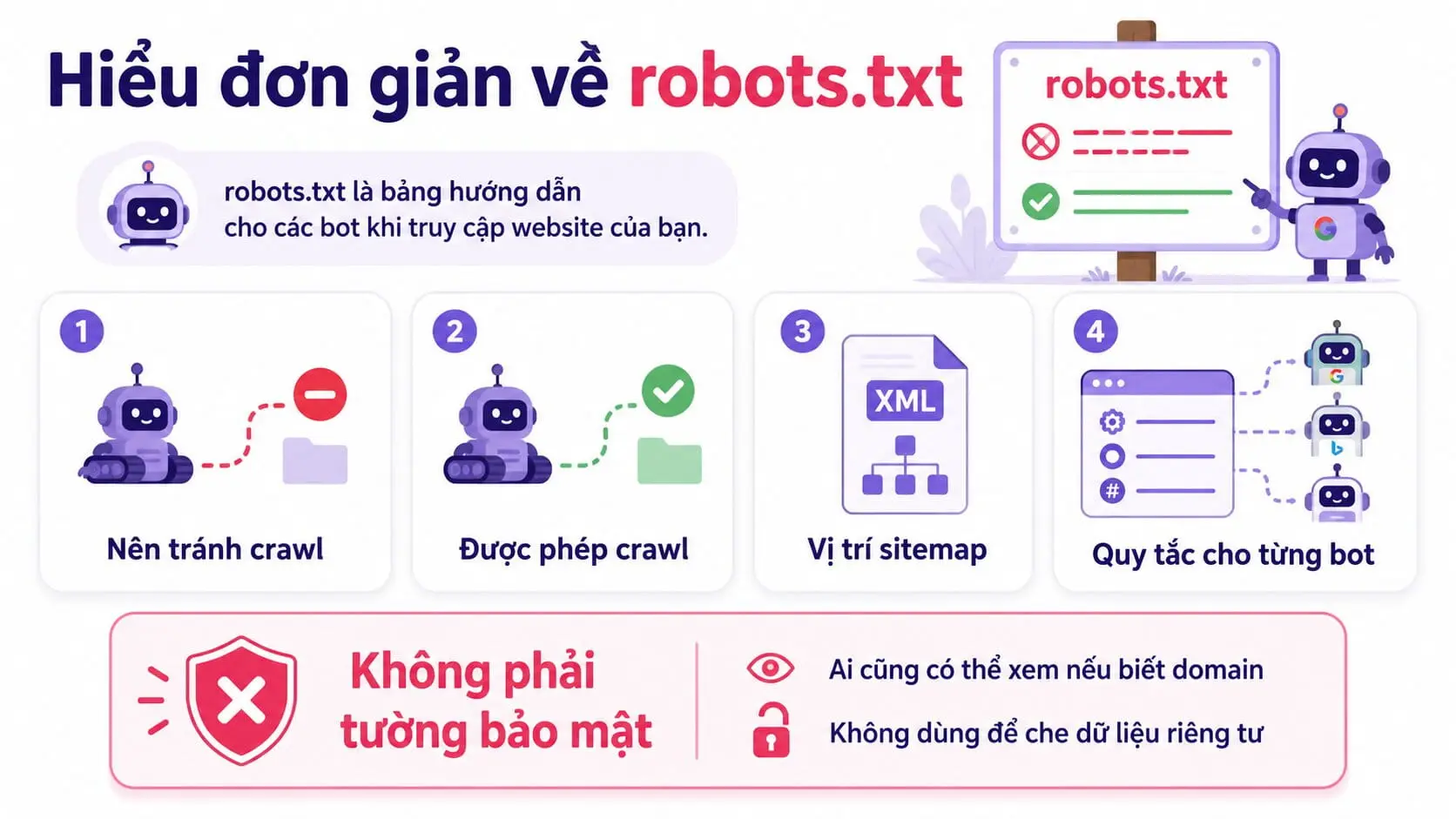
Robots.txt là một file văn bản công khai dùng để đưa ra chỉ dẫn cho các crawler khi chúng truy cập website. Crawler có thể là Googlebot, Bingbot hoặc các bot khác dùng để thu thập dữ liệu trên web.
File này thường nằm tại thư mục gốc của domain. Ví dụ, nếu website là example.com, file hợp lệ thường nằm ở example.com/robots.txt. Google cũng nêu rõ robots.txt chỉ áp dụng cho đúng protocol, host và port nơi file được đặt, nên subdomain hoặc phiên bản HTTP/HTTPS có thể cần file riêng nếu cấu trúc website tách biệt.
Nói đơn giản, robots.txt giống một bảng chỉ dẫn cho bot:
- Khu vực nào nên tránh crawl.
- Khu vực nào vẫn được phép crawl.
- Sitemap của website nằm ở đâu.
- Quy tắc nào áp dụng cho bot nào.
Tuy nhiên, robots.txt không phải tường bảo mật. Bất kỳ ai cũng có thể mở file này trên trình duyệt nếu biết domain. Vì vậy, không nên dùng robots.txt để che giấu dữ liệu riêng tư, trang nội bộ hoặc tài nguyên nhạy cảm.
Robots.txt hoạt động như thế nào?
Khi crawler truy cập một website, nó có thể kiểm tra robots.txt trước để biết website có quy tắc crawl nào không. Sau đó, crawler đọc nhóm quy tắc tương ứng với user-agent của mình và quyết định URL nào có thể request.
Một file robots.txt thường có nhiều nhóm quy tắc. Mỗi nhóm bắt đầu bằng User-agent, sau đó là các dòng Disallow hoặc Allow. Nếu không có quy tắc chặn phù hợp, crawler thường có thể truy cập URL.
Ví dụ cơ bản:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
Trong ví dụ này:
- User-agent: * áp dụng cho mọi crawler.
- Disallow: /wp-admin/ yêu cầu bot không crawl thư mục quản trị.
- Allow: /wp-admin/admin-ajax.php cho phép crawl một file cụ thể bên trong khu vực bị chặn.
- Sitemap: khai báo vị trí sitemap XML.
Google hỗ trợ các trường như user-agent, allow, disallow và sitemap. Một số quy tắc không chính thức như crawl-delay không được Googlebot xử lý trong robots.txt.
Robots.txt khác gì với noindex, meta robots và X-Robots-Tag?
Robots.txt kiểm soát crawl, còn noindex, meta robots và X-Robots-Tag kiểm soát việc một trang hoặc tài nguyên có được lập chỉ mục hay không. Đây là điểm rất dễ nhầm trong SEO.
|
Nhu cầu |
Công cụ phù hợp |
Lý do |
|
Không muốn bot crawl một thư mục |
Robots.txt |
Chặn crawler request URL |
|
Không muốn một trang HTML xuất hiện trên Google |
Meta robots noindex |
Google cần đọc trang để thấy lệnh noindex |
|
Không muốn index file PDF hoặc tài nguyên không phải HTML |
X-Robots-Tag |
Chỉ thị index nằm trong HTTP header |
|
Muốn bảo vệ dữ liệu riêng tư |
Đăng nhập, phân quyền, mật khẩu |
Robots.txt là file công khai |
|
Muốn khai báo URL quan trọng |
XML sitemap |
Hỗ trợ crawler tìm URL cần crawl |
Điểm quan trọng là Disallow không đồng nghĩa với xóa khỏi Google. Nếu một URL bị chặn crawl nhưng vẫn được liên kết từ nơi khác, URL đó vẫn có thể xuất hiện trên Google ở dạng hạn chế vì Google biết URL tồn tại nhưng không đọc được nội dung trang.
Google cũng khuyến nghị dùng noindex hoặc bảo vệ bằng mật khẩu nếu mục tiêu là ngăn trang xuất hiện trên kết quả tìm kiếm.
Do đó, trước khi sửa robots.txt, cần hỏi đúng mục tiêu:
- Muốn giảm bot crawl khu vực không cần thiết?
- Muốn ngăn trang xuất hiện trên Google?
- Muốn bảo vệ dữ liệu?
- Muốn khai báo sitemap?
Mỗi mục tiêu cần một công cụ khác nhau. Dùng sai công cụ có thể khiến website chặn nhầm crawler hoặc vẫn để lộ URL không mong muốn.

Robots.txt có ảnh hưởng đến SEO không?
Robots.txt có thể ảnh hưởng đến SEO thông qua khả năng crawler truy cập nội dung. Tuy nhiên, file này không tự giúp website tăng thứ hạng và cũng không thay thế các yếu tố như nội dung, internal link, canonical, tốc độ tải trang hoặc trải nghiệm người dùng.
Robots.txt có ích trong một số trường hợp:
- Hạn chế crawler truy cập khu vực quản trị.
- Giảm crawl vào URL không quan trọng.
- Khai báo vị trí XML sitemap.
- Tránh bot đi vào một số đường dẫn tạo nhiều biến thể.
- Kiểm soát crawl ở website lớn có nhiều tham số URL.
Ngược lại, robots.txt cũng có thể gây lỗi SEO nếu cấu hình sai. Một dòng Disallow: / có thể khiến crawler không truy cập được toàn bộ website. Một rule chặn CSS hoặc JavaScript quan trọng cũng có thể làm Google khó render trang như người dùng nhìn thấy.
Vì vậy, robots.txt nên được xem là công cụ điều phối crawl. Nó không phải mẹo SEO để cải thiện ranking, cũng không phải nơi đặt mọi quy tắc kỹ thuật của website.
Cú pháp robots.txt cơ bản cần biết
Một file robots.txt dễ đọc thường chỉ cần vài nhóm lệnh đơn giản. Không nên làm file quá phức tạp nếu website không có nhu cầu crawl control đặc biệt.
|
Dòng lệnh |
Ý nghĩa |
|
User-agent |
Chỉ bot hoặc nhóm bot mà quy tắc áp dụng |
|
Disallow |
Đường dẫn không muốn bot crawl |
|
Allow |
Đường dẫn vẫn cho phép crawl trong khu vực bị chặn |
|
Sitemap |
Khai báo vị trí sitemap XML |
|
* |
Ký tự đại diện cho nhiều chuỗi ký tự |
|
$ |
Đánh dấu kết thúc URL trong một số quy tắc |
|
# |
Ghi chú, crawler bỏ qua phần sau dấu này |
Ví dụ:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
Một số lưu ý thực tế:
- Tên file phải là robots.txt.
- File nên ở dạng plain text.
- File cần nằm ở thư mục gốc của host.
- Nên dùng mã hóa UTF-8.
- Đường dẫn trong robots.txt có thể phân biệt chữ hoa và chữ thường tùy server.
- Không dùng file Word hoặc định dạng giàu ký tự để tạo robots.txt.
Google nêu rằng robots.txt phải là file plain text mã hóa UTF-8, và các dòng không hợp lệ có thể bị bỏ qua khi Google phân tích file.
Các mẫu robots.txt thường dùng
Không có một mẫu robots.txt “chuẩn SEO” cho mọi website. Mẫu phù hợp phụ thuộc vào CMS, cấu trúc URL, môi trường staging, sitemap và chiến lược index của từng site.
Mẫu cho website cho phép crawl toàn bộ
Mẫu này phù hợp với website nhỏ, không cần chặn thư mục đặc biệt:
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
Nhiều website đơn giản thậm chí không cần file phức tạp. Nếu không có khu vực cần chặn, việc để crawler truy cập bình thường có thể đã đủ.
Mẫu chặn toàn bộ website tạm thời
Mẫu này chỉ nên dùng cho môi trường staging hoặc website chưa muốn public:
User-agent: *
Disallow: /
Đây là dòng rất nguy hiểm nếu để sót trên production. Khi website live, cần kiểm tra lại để tránh chặn toàn bộ crawler khỏi nội dung chính.
Mẫu WordPress cơ bản
Với WordPress, mẫu thường gặp là:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
Mẫu này chặn khu vực quản trị nhưng vẫn cho phép admin-ajax.php, vì một số theme hoặc plugin có thể cần file này để hoạt động bình thường.
Tuy nhiên, không nên copy mẫu này một cách máy móc. Website thương mại điện tử, website có membership, nhiều ngôn ngữ hoặc nhiều subdomain có thể cần cấu hình khác.
Mẫu chặn trang tìm kiếm nội bộ
Một số website muốn hạn chế crawler đi vào trang tìm kiếm nội bộ:
User-agent: *
Disallow: /?s=
Disallow: /search/
Trước khi dùng, cần kiểm tra cấu trúc URL thật của website. Không phải website nào cũng dùng /search/ hoặc ?s= cho trang tìm kiếm.
Cách tạo file robots.txt trên WordPress
Website WordPress có thể tạo robots.txt bằng plugin SEO, bằng hosting/FTP hoặc dùng file ảo do WordPress sinh ra. Cách phù hợp phụ thuộc vào quyền truy cập và mức độ quen thuộc với kỹ thuật.
|
Cách tạo |
Phù hợp khi |
Điểm cần lưu ý |
|
Plugin SEO |
Người dùng không muốn thao tác hosting |
Không nên để nhiều plugin cùng chỉnh file |
|
Hosting hoặc FTP |
Có quyền truy cập thư mục gốc |
Cần backup trước khi sửa |
|
File ảo WordPress |
Website chưa có file vật lý |
Cần kiểm tra output thật trên trình duyệt |
Tạo bằng plugin SEO
Một số plugin SEO cho phép chỉnh robots.txt ngay trong dashboard WordPress. Cách này phù hợp với người không muốn vào hosting hoặc FTP.
Quy trình thường gồm:
- Mở khu vực công cụ của plugin SEO.
- Tìm phần chỉnh robots.txt.
- Thêm hoặc sửa quy tắc cần thiết.
- Lưu lại.
- Mở file trên trình duyệt để kiểm tra.
Điểm cần chú ý là không nên cài nhiều plugin cùng can thiệp robots.txt. Nếu theme, plugin bảo mật và plugin SEO cùng chỉnh file, output cuối cùng có thể khác với phần bạn nhìn thấy trong từng plugin.
Tạo thủ công qua hosting hoặc FTP
Nếu có quyền truy cập file server, có thể tạo file thủ công:
- Tạo file tên robots.txt.
- Lưu ở định dạng plain text.
- Upload lên thư mục gốc của website.
- Mở domain.com/robots.txt để kiểm tra.
- Test các URL quan trọng trong Google Search Console.
Cách này phù hợp khi website cần kiểm soát chính xác file thật trên server. Tuy nhiên, nên backup trước khi sửa để có thể khôi phục nhanh nếu rule mới gây lỗi.
Khi nào không nên tự sửa robots.txt?
Không nên tự chỉnh robots.txt nếu bạn chưa rõ URL nào cần crawl, URL nào cần index và URL nào chỉ là biến thể kỹ thuật.
Các trường hợp nên kiểm tra kỹ hơn:
- Website thương mại điện tử có nhiều filter.
- Website đang redesign hoặc migrate.
- Website có staging và production song song.
- Website có nhiều subdomain.
- Website có nhiều plugin SEO hoặc bảo mật.
- Website đang gặp lỗi index hàng loạt.
Với các trường hợp này, robots.txt cần được xem cùng sitemap, canonical, noindex, internal link và báo cáo Google Search Console.
Cách kiểm tra file robots.txt
Sau khi tạo hoặc sửa robots.txt, cần kiểm tra file có truy cập công khai được không, cú pháp có hợp lý không và URL quan trọng có bị chặn nhầm không.
Checklist cơ bản:
- Mở domain.com/robots.txt bằng trình duyệt ẩn danh.
- Kiểm tra file có trả về nội dung text, không phải trang HTML lỗi.
- Kiểm tra HTTP status là 200.
- Kiểm tra file nằm đúng thư mục gốc.
- Kiểm tra không còn Disallow: / sau khi website live.
- Kiểm tra sitemap dùng URL tuyệt đối và đúng domain.
- Kiểm tra CSS, JavaScript và hình ảnh quan trọng không bị chặn nhầm.
- Test các URL quan trọng bằng URL Inspection trong Google Search Console.
Google khuyến nghị sau khi tạo robots.txt, cần upload file vào root domain và kiểm tra để đảm bảo file có thể truy cập công khai.
Một điểm thực tế là robots.txt có thể được cache. Vì vậy, sau khi sửa file, Googlebot có thể cần thời gian để cập nhật. Nếu website vừa gỡ chặn một URL quan trọng, nên kiểm tra lại trong Search Console và theo dõi trạng thái crawl/index sau khi Google thu thập lại dữ liệu.
Những lỗi robots.txt thường gặp
Lỗi robots.txt thường nguy hiểm vì chỉ một dòng cấu hình sai cũng có thể làm crawler không truy cập được nội dung quan trọng. Đây là những lỗi nên tránh khi tối ưu website.
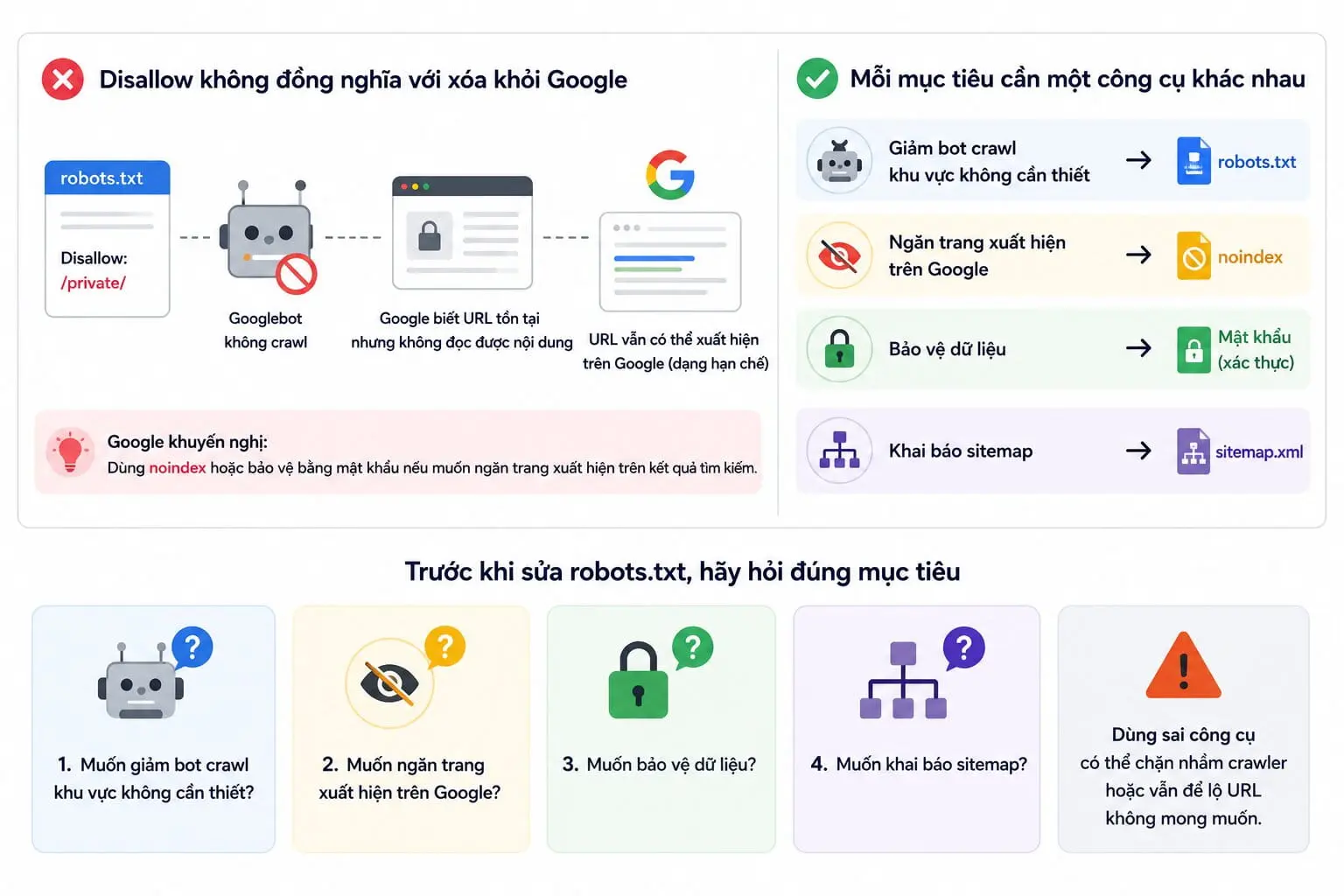
Sai lầm lớn nhất là dùng robots.txt như công cụ bảo mật. Vì file này công khai, việc đưa đường dẫn nhạy cảm vào robots.txt đôi khi còn làm người khác biết website đang có khu vực nào cần chú ý.
Nếu dữ liệu cần bảo vệ, hãy dùng đăng nhập, phân quyền, giới hạn truy cập hoặc cơ chế bảo mật phù hợp. Robots.txt chỉ là chỉ dẫn dành cho crawler, không phải cơ chế khóa dữ liệu.
Có nên dùng robots.txt để chặn AI crawler không?
Robots.txt có thể được dùng để đưa ra chỉ dẫn cho một số AI crawler, nhưng đây vẫn là cơ chế tự nguyện. Không phải mọi crawler trên internet đều tuân thủ robots.txt, nên file này không thay thế chính sách dữ liệu hoặc kiểm soát truy cập thật.
Nếu website có chính sách rõ về việc sử dụng nội dung để huấn luyện hoặc trích xuất dữ liệu, team có thể thêm rule cho từng user-agent cụ thể. Tuy nhiên, cần hiểu rằng điều này chỉ gửi tín hiệu cho crawler có thiện chí tuân thủ.
Với nội dung nhạy cảm, dữ liệu khách hàng, tài liệu nội bộ hoặc khu vực trả phí, robots.txt không đủ. Những nội dung này nên được bảo vệ bằng đăng nhập, phân quyền hoặc hệ thống kiểm soát truy cập ở phía server.
Câu hỏi thường gặp về robots.txt
Robots.txt có chặn index không?
Robots.txt không phải công cụ chặn index tuyệt đối. File này chủ yếu kiểm soát crawler có được truy cập URL hay không. Nếu một URL bị chặn crawl nhưng vẫn có link từ nơi khác, Google vẫn có thể biết URL tồn tại. Muốn chặn index, thường nên dùng noindex hoặc bảo vệ bằng mật khẩu tùy trường hợp.
Website không có robots.txt có sao không?
Website không có robots.txt vẫn có thể được crawler truy cập nếu không có cơ chế chặn khác. Với website nhỏ, không cần crawl control đặc biệt, việc không có file phức tạp không phải vấn đề lớn. Tuy nhiên, robots.txt vẫn hữu ích khi cần khai báo sitemap hoặc hạn chế bot vào một số khu vực.
File robots.txt nằm ở đâu?
File robots.txt nên nằm ở thư mục gốc của host, chẳng hạn example.com/robots.txt. File đặt trong subfolder như example.com/pages/robots.txt không kiểm soát crawl cho toàn bộ host. Với subdomain riêng, cần kiểm tra file robots.txt ở đúng subdomain đó.
Disallow: / nghĩa là gì?
Disallow: / nghĩa là yêu cầu crawler không truy cập toàn bộ website trong phạm vi áp dụng của file robots.txt. Dòng này thường chỉ nên dùng cho môi trường staging hoặc website chưa muốn public. Nếu để trên website live, crawler có thể không truy cập được nội dung quan trọng.
Có nên chặn wp-admin trong robots.txt không?
Với WordPress, chặn /wp-admin/ là cách thường gặp vì khu vực quản trị không cần crawler truy cập. Tuy nhiên, nên cho phép /wp-admin/admin-ajax.php nếu website hoặc plugin cần file này để vận hành đúng. Sau khi sửa, cần kiểm tra giao diện và khả năng crawl của các trang quan trọng.
Robots.txt có bảo vệ dữ liệu riêng tư không?
Không. Robots.txt là file công khai và chỉ hoạt động như chỉ dẫn cho crawler. Dữ liệu riêng tư, trang nội bộ hoặc tài nguyên nhạy cảm cần được bảo vệ bằng đăng nhập, phân quyền hoặc cơ chế kiểm soát truy cập phía server.
Google có hỗ trợ crawl-delay trong robots.txt không?
Googlebot không xử lý quy tắc crawl-delay trong robots.txt. Nếu website gặp vấn đề do bot request quá nhiều, cần kiểm tra hiệu suất server, log crawl và các thiết lập phù hợp khác thay vì chỉ thêm crawl-delay.
Kết luận
Robots.txt là công cụ quản lý crawl, không phải nút chặn index hay lớp bảo mật cho website. Một file tốt thường đơn giản, đúng mục tiêu và dễ kiểm tra. Với WordPress, phần lớn website chỉ cần chặn khu vực quản trị, khai báo sitemap và tránh sửa file khi chưa rõ tác động.
Khi website lớn hơn, robots.txt cần được kiểm tra cùng sitemap, canonical, noindex, internal link và dữ liệu trong Google Search Console để tránh chặn nhầm các URL quan trọng.

BÀI VIẾT MỚI NHẤT
- Spam mail là gì? Tìm hiểu nguyên nhân và phòng tránh spam mail
- Tìm hiểu cấu trúc 4ps trong content writing? Bí quyết giúp content thu hút
- Hướng dẫn kiếm tiền từ Facebook Ad Breaks hiệu quả
- Kế hoạch Facebook marketing: Vai trò quan trọng và cách triển khai phù hợp
- Bật Mí Cách Chạy Quảng Cáo Instagram Hiệu Quả Nhất
Đọc thêm