
Crawl Budget Explained: How Googlebot Finds and Prioritizes Your Pages
Vincent
16/01/2026
22
In technical SEO, crawl budget is the number of URLs Googlebot can and wants to crawl on a website within a given period. It depends on crawl capacity, demand, server performance, URL quality, internal links, sitemaps, and page freshness. For SEO teams, it matters most when valuable pages are not discovered or refreshed quickly.
What is crawl budget?
Crawl budget is the amount of attention Googlebot gives to a website when discovering and refreshing URLs. It combines what your server can handle with what Google considers worth crawling.
Googlebot does not crawl every URL on every website at the same frequency. Some pages are crawled often because they are important, fresh, internally linked, or frequently updated. Other pages may be crawled rarely because they are buried deep, duplicated, low-value, or technically difficult to access.
A simple way to understand crawl budget is to think of three questions:
- Can Googlebot access the page efficiently?
- Does Google have enough reason to crawl it?
- Does the website guide Googlebot toward the right URLs?
Crawl budget is not only a concern for huge websites. Small sites can also experience crawl inefficiency if they have broken links, duplicate pages, slow hosting, or incorrect indexation rules. However, crawl budget becomes more serious as URL count and update frequency increase.
Crawl capacity vs. crawl demand
Crawl capacity and crawl demand are the two core forces behind crawl budget. Crawl capacity reflects how much crawling your server can support, while crawl demand reflects how much Google wants to crawl your pages.
Crawl capacity depends on server health. If pages respond quickly and errors are low, Googlebot can crawl more efficiently. If response times are high, 5xx errors increase, or the server slows under load, Googlebot may reduce activity to avoid harming user experience.
Crawl demand depends on page importance and freshness. Pages with strong internal links, backlinks, traffic, updates, and search value can attract more crawling. Stale, duplicated, or low-value pages usually create weaker demand.
| Factor | Crawl capacity | Crawl demand |
| Main question | Can the server handle crawling? | Does Google want to crawl these URLs? |
| Influenced by | Speed, hosting, errors, availability | Popularity, freshness, quality, links |
| SEO risk | Googlebot slows down requests | Important pages receive low attention |
| Main fix | Improve performance and stability | Improve value, links, and freshness |
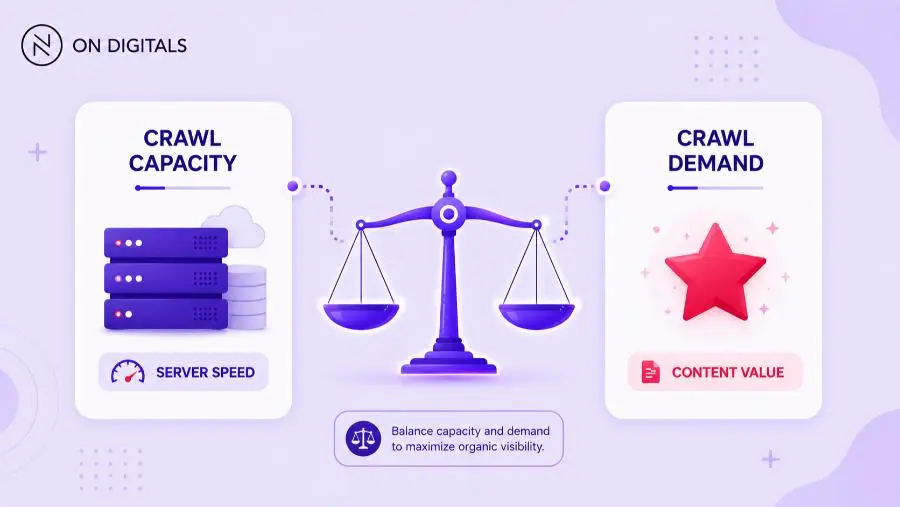
Good crawl budget optimization balances both sides. A fast server will not help much if most URLs are duplicates. Strong content will still struggle if the server responds slowly or blocks important resources.
Why crawl budget matters for SEO
Crawl budget matters because crawling is the first step before indexing and ranking. If Googlebot does not crawl a page, Google cannot fully evaluate it for search results.
This affects three common SEO scenarios. First, new pages may take longer to enter the index. Second, updated pages may take longer to reflect content improvements, technical fixes, or keyword changes. Third, search engines may spend too much time crawling pages that do not support traffic or conversions.
For example, a B2B website may publish new service pages but bury them five clicks away from the homepage. Googlebot may continue crawling old blog tags and archive pages while missing the new commercial pages. In that case, the problem is not only content quality. It is also crawl prioritization.
Crawl budget also matters after technical changes. Website migrations, URL restructuring, HTTPS changes, CMS updates, and JavaScript redesigns can all affect how search engines access pages. Monitoring crawl activity helps SEO teams catch problems early.
When should businesses care about crawl budget?
Businesses should care about crawl budget when important pages are slow to index, crawl errors are increasing, or search engines spend attention on low-value URLs. The issue becomes more urgent when the website has many pages or changes often.
Crawl budget is usually worth reviewing for:
- Ecommerce websites with products, categories, and filters.
- Publishers with frequent article updates.
- B2B websites with many landing pages.
- Multilingual websites with hreflang structures.
- Marketplaces with user-generated URLs.
- Websites that recently migrated or redesigned.
- Sites with many “Discovered – currently not indexed” URLs.
A small five-page brochure website rarely needs advanced crawl budget work. A 50,000-page website with faceted navigation, expired products, and duplicated parameters does. The practical question is not website size alone. The real question is whether valuable pages compete with wasteful URLs for crawler attention.
Common causes of crawl budget waste
Crawl budget waste happens when search engines spend requests on URLs that do not deserve crawling or indexing. These URLs may be broken, duplicated, blocked incorrectly, or too weak to support search visibility.
The most common causes include:
- Redirect chains: Googlebot follows multiple hops before reaching the final page.
- 404 and soft 404 pages: Broken or thin pages consume unnecessary requests.
- Duplicate URLs: HTTP, HTTPS, www, non-www, trailing slash, and parameter versions compete.
- Faceted navigation: Filters generate many near-duplicate URL combinations.
- Thin content: Weak pages receive crawl attention without earning indexation.
- Orphan pages: URLs exist but lack internal links from the main site.
- Outdated sitemaps: Removed or non-indexable URLs remain submitted.
- Slow server response: Googlebot crawls fewer URLs within the same time.
These issues often appear together. For example, an ecommerce site may have slow category pages, product filters, discontinued product URLs, and old XML sitemap entries. Fixing only one issue may not solve the larger crawl waste problem.
How to optimize crawl budget?
Crawl budget optimization should help Googlebot find important pages faster and avoid unnecessary URLs. The best process combines technical cleanup, internal linking, sitemap control, and content quality improvements.
1. Improve website speed and server stability
Server performance affects how efficiently Googlebot can crawl. Slow response times, timeouts, and 5xx errors reduce crawl efficiency and may limit how many pages Googlebot requests.
Improve crawl capacity by using server-side caching, reducing database bottlenecks, compressing resources, optimizing images, and using a reliable hosting setup. For global sites, a CDN can reduce load on the origin server and improve delivery of static resources.
2. Keep XML sitemaps clean
XML sitemaps should include indexable, canonical, valuable URLs. They should not include redirected pages, 404 pages, noindex pages, duplicate URLs, or outdated temporary pages.
A clean sitemap helps Google understand which URLs matter. It does not guarantee crawling or indexing, but it improves discovery signals. Update sitemaps after content pruning, URL changes, product removals, and large publishing batches.
3. Reduce duplicate and low-value URLs
Duplicate URLs waste crawler time and dilute signals. Use canonical tags, redirects, parameter handling, and content consolidation to reduce duplication.
Low-value pages require a business decision. Some pages should be improved because they target useful search demand. Others should be merged, noindexed, removed, or excluded from sitemaps. Avoid keeping weak pages only because they already exist.
4. Strengthen internal linking
Internal links guide Googlebot to important pages. Pages closer to the homepage and linked from relevant hubs usually receive stronger crawl signals.
Review important pages that sit too deep in the structure. Add links from category pages, service hubs, related blog posts, and navigation modules. Use descriptive anchor text that reflects the destination page, not generic text such as “read more.”
5. Fix crawl errors and redirect chains
Crawl errors waste requests and reduce trust in site quality. Review 404s, soft 404s, blocked resources, redirect chains, and server errors regularly.
Redirect removed URLs only when there is a relevant replacement. Do not redirect every deleted URL to the homepage. For permanently removed content with no replacement, a 404 or 410 status may be more appropriate.
Crawl budget myths to avoid
Crawl budget is often misunderstood, which leads to poor technical SEO decisions. The biggest myth is that every website needs aggressive crawl budget optimization. Many small sites only need clean sitemaps, healthy indexation, and basic technical SEO.
Another myth is that more crawling always means better SEO. More crawling is useful only when Googlebot spends that activity on valuable, indexable pages. More crawling of duplicate parameters, broken URLs, or low-quality pages is still waste.
A third myth is that robots.txt can remove pages from search results. Robots.txt can stop crawling, but blocked URLs may still appear in search if Google discovers them through links. Use the correct indexation method based on your goal.
The final myth is that crawl budget optimization directly raises rankings. Crawl budget supports ranking potential by improving discovery and freshness. Rankings still depend on relevance, quality, authority, user intent, and technical accessibility.
How to measure crawl budget performance
Measure crawl budget performance by checking whether important pages are crawled, indexed, and refreshed efficiently. Do not rely on one metric alone.
Start with Google Search Console. Review Crawl Stats, Page Indexing, sitemap reports, and URL Inspection. Then use a crawler to check indexability, internal links, depth, canonical tags, and status codes. For larger sites, use server log analysis to confirm actual Googlebot behavior.
Useful metrics include:
- Crawl requests over time.
- Average response time.
- 3xx, 4xx, and 5xx response distribution.
- Crawled vs. indexed URL count.
- Important pages not crawled recently.
- New page time to first crawl.
- Sitemap URLs not indexed.
- Orphan pages and deep pages.
Review trends instead of isolated numbers. A temporary crawl spike after publishing content may be healthy. A sustained spike in 404s after a migration is not.
Frequently asked questions about crawl budget
Is crawl budget a ranking factor?
Crawl budget is not a direct ranking factor. It affects SEO indirectly by influencing how quickly Google discovers, refreshes, and evaluates pages. If valuable pages are not crawled or indexed, they cannot compete effectively in search results, even if their content quality is strong.
How can I check my crawl budget?
You can start by checking the Crawl Stats report in Google Search Console. Review total crawl requests, response time, host status, response codes, and Googlebot types. For deeper analysis, use server logs and a technical crawler to compare actual bot behavior with your site structure.
Does noindex save crawl budget?
Noindex prevents a page from appearing in search results after Google crawls it and sees the directive. It does not stop crawling by itself. If the goal is to reduce crawl waste, review internal links, sitemaps, canonical rules, robots.txt use, and whether the page should exist at all.
How often should crawl budget be optimized?
Most stable websites can review crawl budget quarterly. Websites with migrations, frequent publishing, ecommerce filters, or many technical changes should review it monthly or weekly during high-risk periods. The review frequency should match the speed at which the website changes.
What is the fastest way to reduce crawl waste?
The fastest way is to remove obvious technical waste first. Clean XML sitemaps, fix broken links, reduce redirect chains, remove expired URLs, and stop internally linking to low-value pages. Then review duplicate templates, faceted URLs, and thin content for deeper structural fixes.
Conclusion
Crawl budget helps explain how Googlebot chooses what to crawl and how efficiently it can crawl it. For SEO teams, the main goal is not to chase higher crawl numbers. The goal is to guide Googlebot toward pages that deserve discovery, indexation, and regular refreshes.
A healthy crawl budget strategy starts with fast servers, clean sitemaps, strong internal links, controlled duplicates, and useful content. When crawl issues become complex, crawl budget monitoring tools can reveal where search engines spend attention and which fixes should come first.
On Digitals helps businesses connect technical SEO, content structure, and performance data so crawl budget work supports real organic growth.

NEWEST POSTS
- Advertising Industry In Vietnam: The 2026 Trends, Channels and Market-Entry Strategy
- Best SEO Company in Vietnam: Latest Shortlist For Businesses
- How To Leverage Social Media For Customer Service Like A Pro?
- Social Media Post Tips – 8 Ways To Boost Engagement
- How To Use Social Media for Sales – In-depth Beginner Guide
Read more